7 推測統計
データの可視化では、推測統計量のプロットを含めることがしばしばである。
library(ggplot2) # 忘れずにパッケージを読み込む7.1 エラーバー
エラーバー(error bar)は誰でも馴染みがあるのではないだろうか。棒グラフとよく一緒にいるアイツのことである。エラーバーはデータの標準誤差(standard error of the mean; SEM20)を表すのに使われることが多い。
ここでは、gcookbookのcabbage_exp(キャベツに関するデータセット)を使ってエラーバーを描いてみよう。
library(gcookbook) # パッケージの読み込みhead(cabbage_exp) #6行のデータなのですべて表示される## Cultivar Date Weight sd n se
## 1 c39 d16 3.18 0.9566144 10 0.30250803
## 2 c39 d20 2.80 0.2788867 10 0.08819171
## 3 c39 d21 2.74 0.9834181 10 0.31098410
## 4 c52 d16 2.26 0.4452215 10 0.14079141
## 5 c52 d20 3.11 0.7908505 10 0.25008887
## 6 c52 d21 1.47 0.2110819 10 0.06674995注目する変数は、
Cultivar:キャベツの品種(c39 or c52)Date:栽培期間Weight:キャベツの平均重量se:キャベツの平均重量の標準誤差
である。平均値を棒グラフで、標準誤差をエラーバーで描いてみよう。コードは以下の通りである。
ggplot(cabbage_exp, aes(Date, Weight, fill = Cultivar)) + # x軸にDate、y軸にWeight、Cultivarごとに色分け
geom_bar(stat = "identity", position = "dodge") + # グルーピングされた棒グラフの復習
geom_errorbar(aes(ymin = Weight - se, ymax = Weight + se), position = position_dodge(width = 0.9), width = 0.2) # ymin:エラーバーの下端、ymax:エラーバーの上端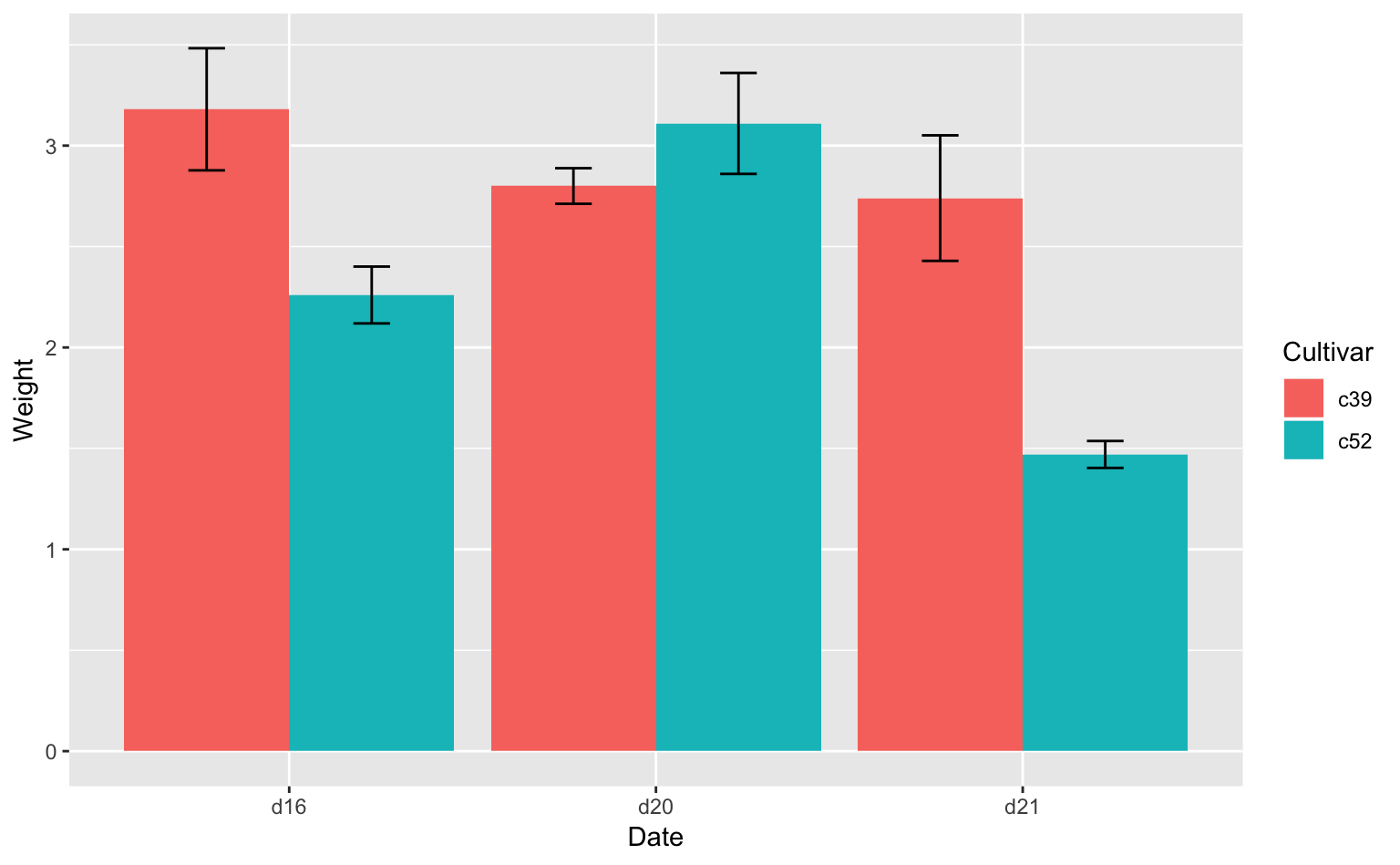
Figure 7.1: エラーバー付きの棒グラフ。エラーバーは標準誤差を表している。
コードの内容を順に解説する。
ggplot(cabbage_exp, aes(Date, Weight, fill = Cultivar)- x軸に
Date、y軸にWeight、グルーピング(塗りつぶし)にCultivarを指定。
- x軸に
geom_bar(stat = "identity", position = "dodge")棒グラフ。
stat = "identity"とする必要がある。また、Cultivarごとに位置をずらすには、position = "dodge"としなければならない。忘れてしまった人は、もう一度Chapter 3を復習しよう。
geom_errorbar(aes(ymin = Weight - se, ymax = Weight + se), position = position_dodge(width = 0.9), width = 0.2)エラーバー。
yminとymaxには、それぞれエラーバーの下端と上端のy座標を指定する。position = position_dodge(width = 0.9)とすることで、エラーバーを棒グラフのように水平方向にずらすことができる。棒グラフのずらし幅が0.9なので、エラーバーのwidth(ずらし幅)も0.9にする21。最後の
widthはエラーバーの横幅を表している。デフォルトだと、棒グラフの棒と同じ幅になる。
なお、エラーバーを描く際は、エラーバーが何を表しているのかをキャプションなどに含めなければならない。なぜなら、エラーバーは標準誤差、95%信頼区間(95% confidence interval; 95% CI)、標準偏差、ベイズ信頼区間など、様々な統計量を表現するのにも使われるからである。
7.2 信頼区間
信頼区間のプロットにもgeom_errorbar()は使えるが、折れ線グラフ(時系列データ)などではgeom_ribbon()の方が良いだろう。ここでは、gcookbookのclimate(気温の時系列データ)を使ってみよう。
head(climate)## Source Year Anomaly1y Anomaly5y Anomaly10y Unc10y
## 1 Berkeley 1800 NA NA -0.435 0.505
## 2 Berkeley 1801 NA NA -0.453 0.493
## 3 Berkeley 1802 NA NA -0.460 0.486
## 4 Berkeley 1803 NA NA -0.493 0.489
## 5 Berkeley 1804 NA NA -0.536 0.483
## 6 Berkeley 1805 NA NA -0.541 0.475なお、ここではSourceが"Berkeley"のデータだけを抽出して可視化を行う。抽出したデータはclimに代入する。以下のコードは今は理解できなくて良い。
library(tidyverse) # データハンドリング用のパッケージ群を読み込むclim = climate %>% # climateデータの
filter(Source == "Berkeley") # Sourceが"Berkeley"の行だけを抽出してくださいプロットするのは以下の変数である。
Year:年Anomaly10y:1951〜1980年の平均気温と比べたときのズレUnc10y:95%信頼区間
では、geom_ribbon()を使ってプロットしてみよう。コードの書き方はgeom_errorbar()に似ている。なお、alphaで信頼区間を半透明にしないと、グラフが真っ黒になってしまうので注意が必要である。
ggplot(clim, aes(Year, Anomaly10y)) +
geom_line() +
geom_ribbon(aes(ymin = Anomaly10y - Unc10y, ymax = Anomaly10y + Unc10y), alpha = 0.2) # alphaで透明度を指定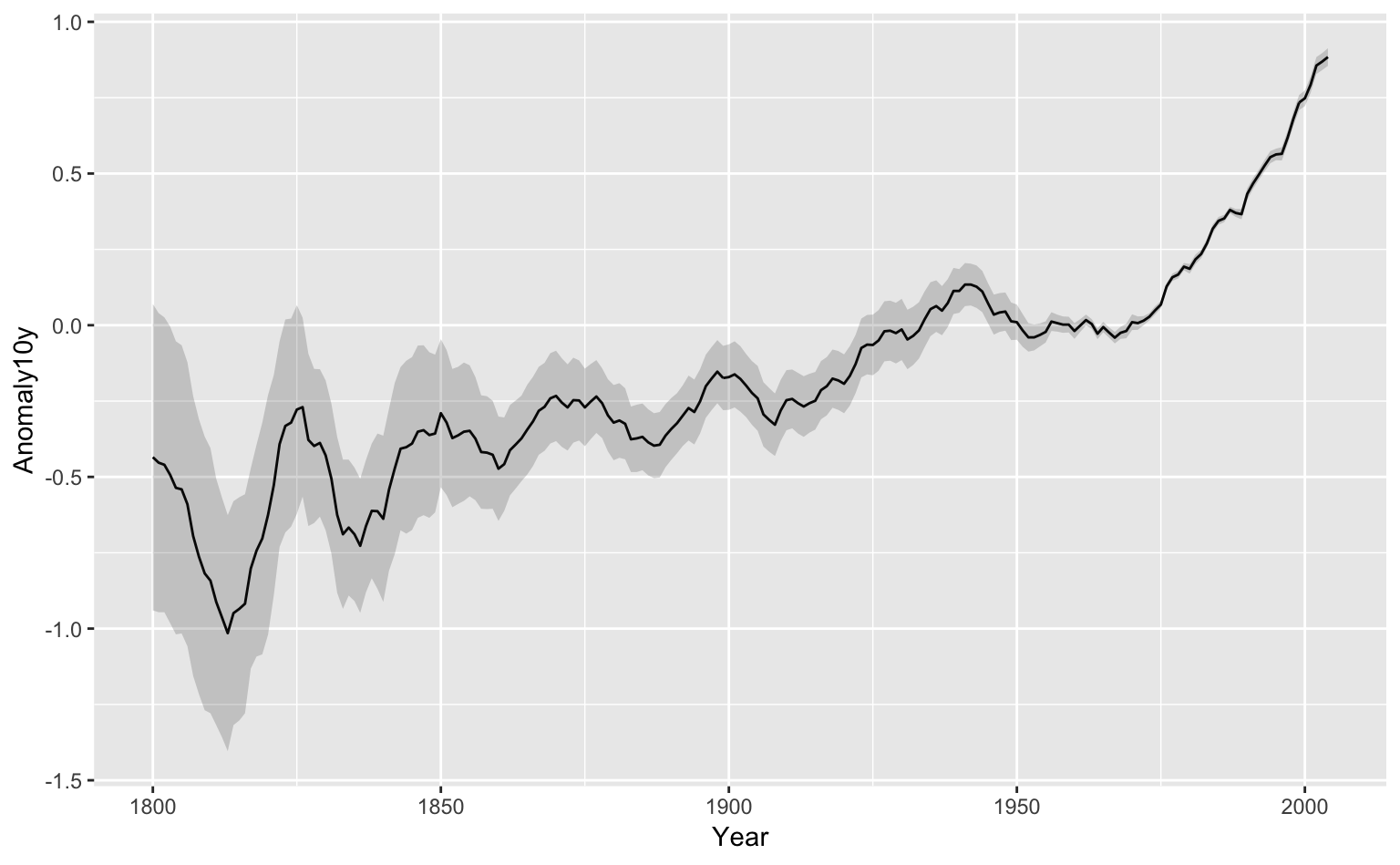
Figure 7.2: 95%信頼区間のプロット。
7.3 回帰直線などのフィッティング
散布図に回帰直線などをフィッティングさせた図を見たことがあるだろう。ggplot2でもそれが可能である。ここでは、gcookbookのheightweight(こどもの身長と体重データ)を使ってみよう。
head(heightweight) # 先頭6行## sex ageYear ageMonth heightIn weightLb
## 1 f 11.92 143 56.3 85.0
## 2 f 12.92 155 62.3 105.0
## 3 f 12.75 153 63.3 108.0
## 4 f 13.42 161 59.0 92.0
## 5 f 15.92 191 62.5 112.5
## 6 f 14.25 171 62.5 112.0まず、geom_point()で身長(heightIn)と体重(WeightLb)の散布図を描き、その上にgeom_smooth()で回帰直線を描いてみよう。なお、回帰直線を引くには、method = lmと指定する必要がある(デフォルトだとLOESS曲線22 が引かれる)。Rにおいてlmは線形モデル(linear model)を表している。
ggplot(heightweight, aes(ageYear, heightIn)) +
geom_point() + # まず散布図
geom_smooth(method = lm) # それから回帰直線;method = lmと指定する必要あり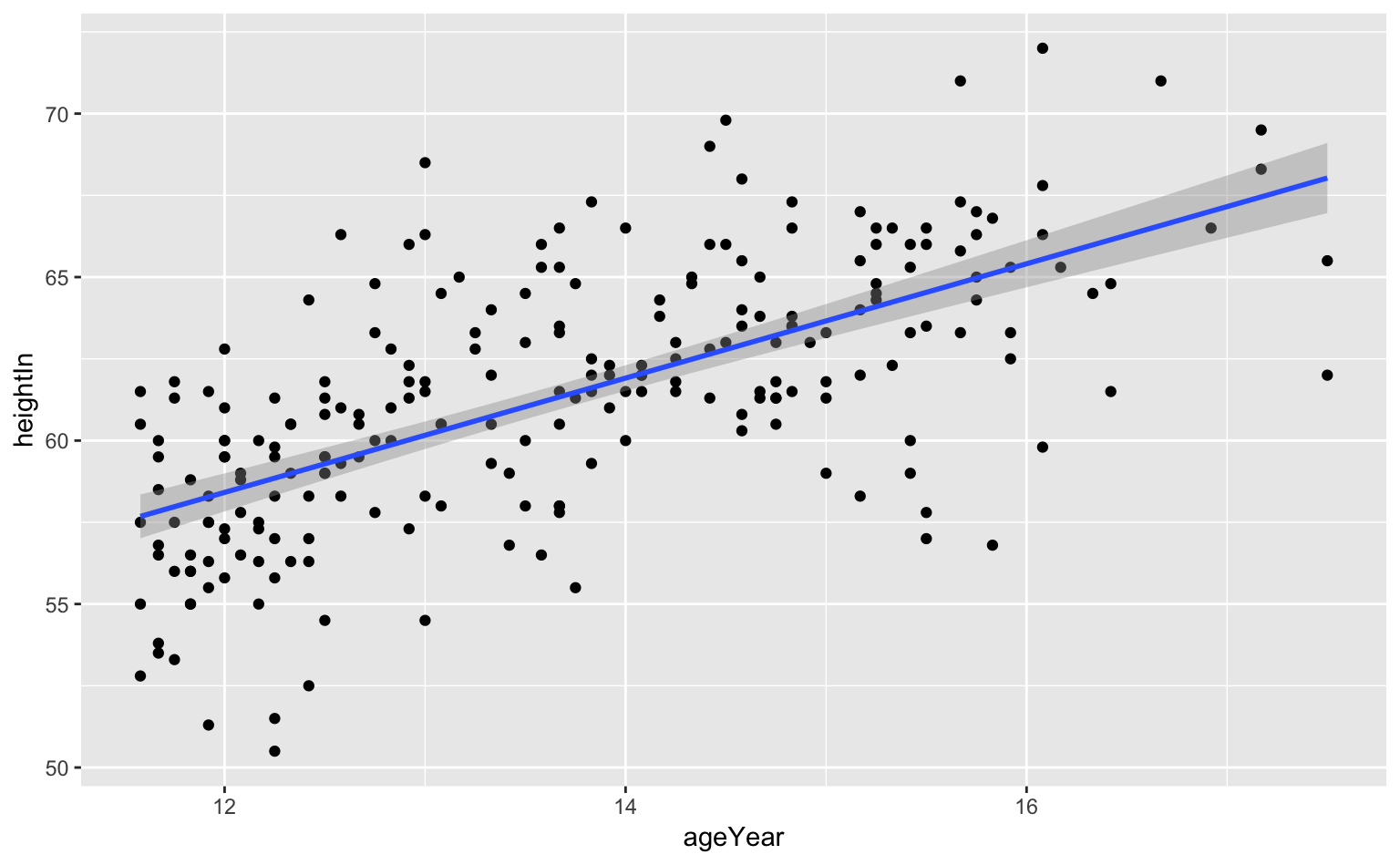
Figure 7.3: 散布図の上に回帰直線を描いたグラフ。網掛けの部分は95%信頼区間を表している。
グループごとに回帰直線を引きたい場合は、fillにグルーピングの変数を指定すれば良い。
ggplot(heightweight, aes(ageYear, heightIn, fill = sex)) + # fill = sexを追加
geom_point() +
geom_smooth(method = lm)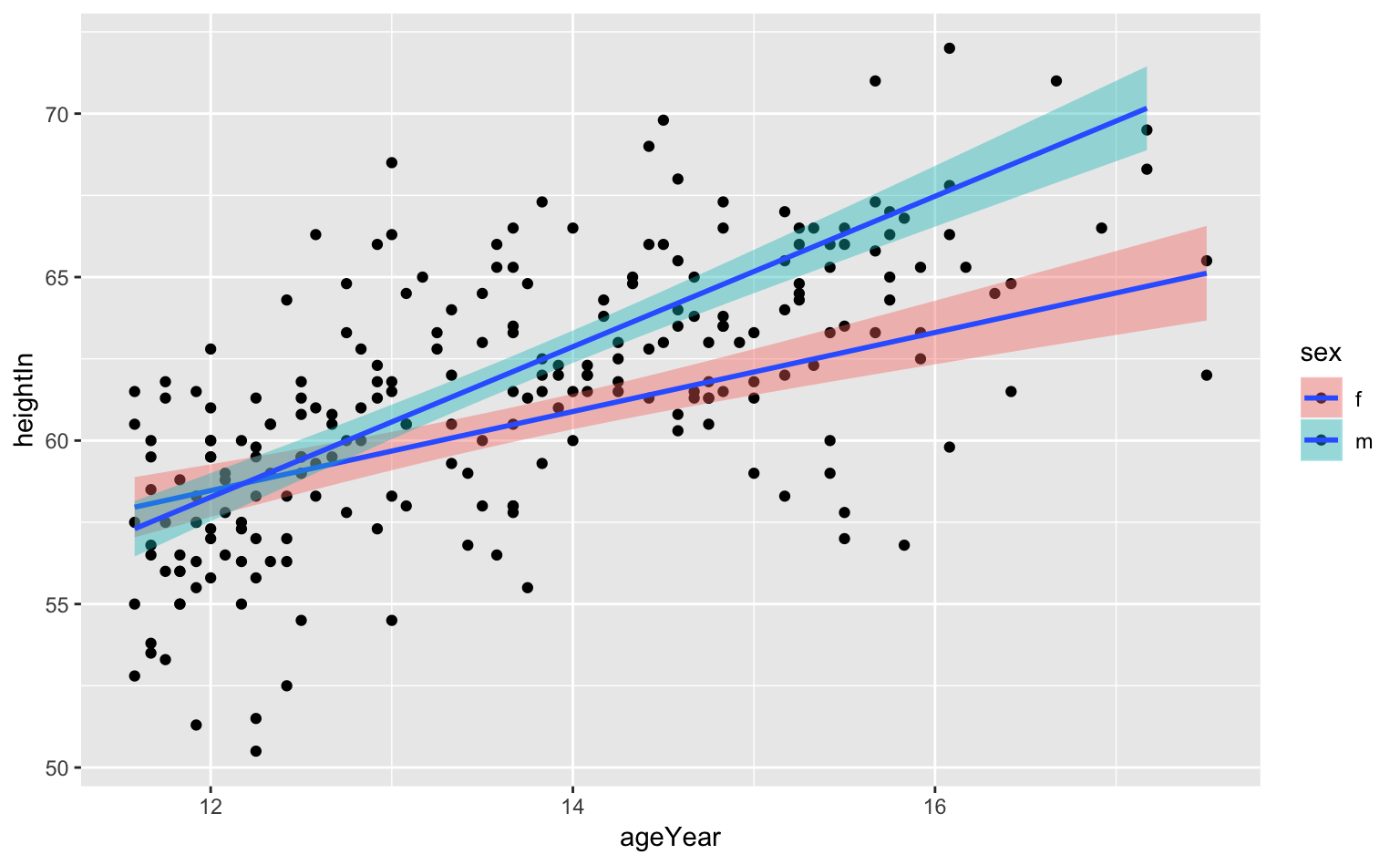
Figure 7.4: こどもの性別ごとに回帰直線を描いたグラフ。網掛けの部分は95%信頼区間を表している。
もちろん、線形モデル以外のフィッティングも可能である。詳しくはGoogle先生が教えてくれるだろう。
7.4 練習問題
Figure 7.1で描いた
cabbage_expデータの平均値と標準誤差を、今度は折れ線グラフとエラーバーで描いてみよう。このとき、エラーバーはどれくらい調整すれば良いだろうか?Rにデフォルトで入っている
faithfulデータの散布図を描き、その上に回帰直線をプロットしてみよう。