3 数量
基本中の基本として、まずはデータの数量(数値、個数、比率、順位など)を可視化してみよう。
library(ggplot2) # 忘れずにパッケージを読み込む3.1 棒グラフ
3.1.1 基本の棒グラフ
数量の可視化で最も代表的、かつ馴染み深いのは棒グラフ(bar graph; bar chart; bar plot)だろう。
まず、最も基本的な棒グラフを描いてみよう。使うデータは、gcookbookパッケージのpg_mean(植物の重さに関するデータセット)である。まず、gcookbookを読み込む。
library(gcookbook)データの中身は以下の通りである。
head(pg_mean) # データが3行しかないのですべて表示される## group weight
## 1 ctrl 5.032
## 2 trt1 4.661
## 3 trt2 5.5262つの変数はそれぞれ
group:実験の条件(3水準)weight:植物の重さの平均値
を表している。素朴に思いつくのは、「条件をx軸に、重さをy軸に取った棒グラフ」だろう。数量を表す棒グラフは、geom_bar()で描くことができる。
ggplot(pg_mean, aes(group, weight)) + # x軸にgroup、y軸にweight
geom_bar(stat = "identity") # 棒グラフ;stat = "identity"が必要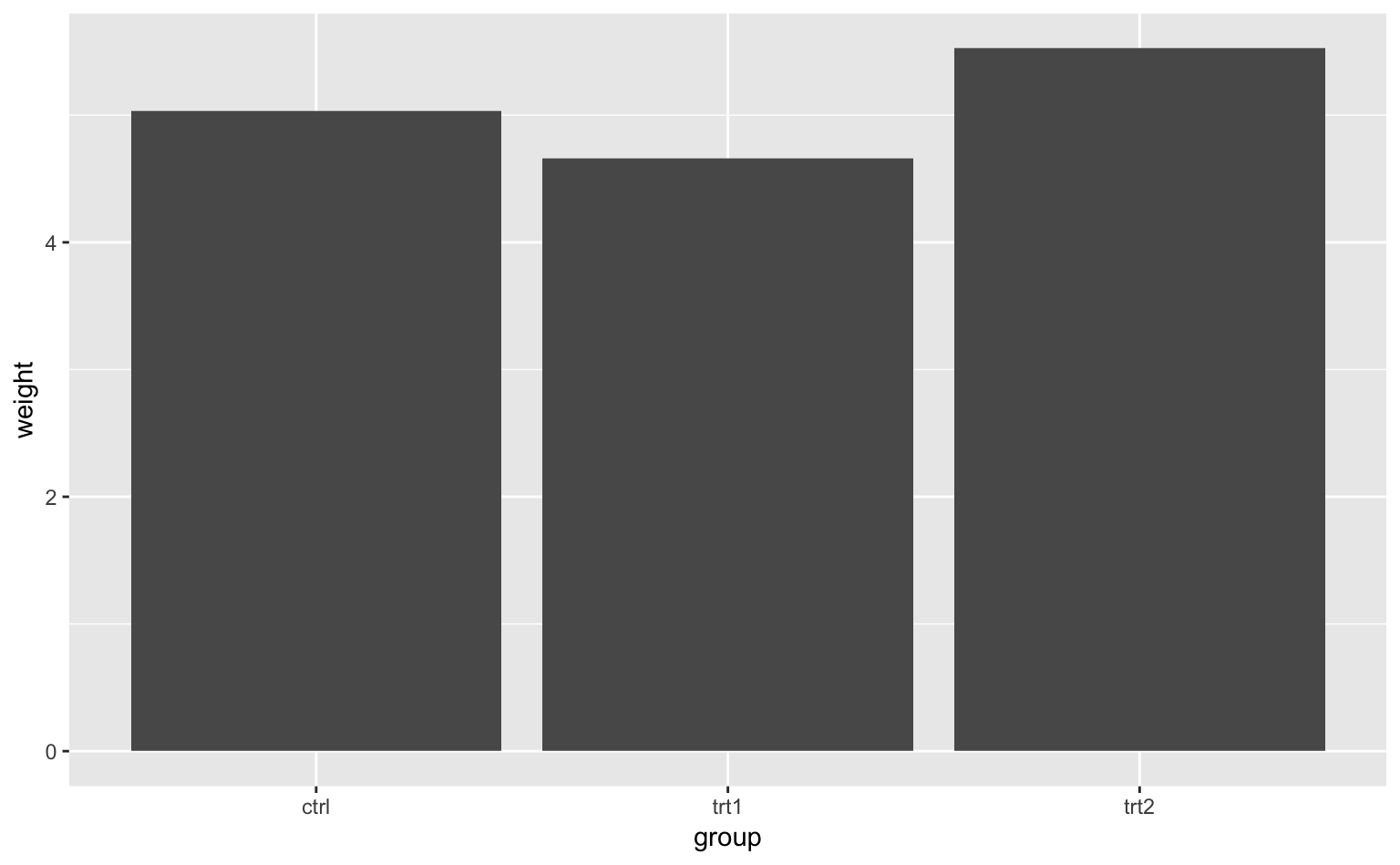
Figure 3.1: 棒グラフ。x軸は条件、y軸は植物の平均重量を表している。
なお、データの数値を棒グラフで描く際は、stat = "identity"と設定する必要がある。なぜなら、geom_bar()は、データの個数を描くのがデフォルト(stat = "count"という設定)になっているからである5。
気になる人は、stat = "identity"の部分を消してコードを実行してみよう。エラー: stat_count() must not be used with a y aesthetic.というメッセージが出てきて、プロットできないはずである6。
3.1.2 グルーピングされた棒グラフ
では、ここに変数を1つ追加してみよう。次に使うデータはgcookbookのcabbage_exp(キャベツに関するデータセット)である。
head(cabbage_exp) # 6行しかないのですべて表示される## Cultivar Date Weight sd n se
## 1 c39 d16 3.18 0.9566144 10 0.30250803
## 2 c39 d20 2.80 0.2788867 10 0.08819171
## 3 c39 d21 2.74 0.9834181 10 0.31098410
## 4 c52 d16 2.26 0.4452215 10 0.14079141
## 5 c52 d20 3.11 0.7908505 10 0.25008887
## 6 c52 d21 1.47 0.2110819 10 0.06674995注目する変数は以下の3つである。
Date:キャベツの栽培期間(d16, d20, or d21)Cultivar:キャベツの品種(c39 or c52)Weight:キャベツの重量(kg)
このとき、栽培期間と品種ごとにキャベツの重量を描いてみたいと思わない人はいない7。このようなときは、Dateをx、Weightをy、Cultivarをfillに対応づけて描けば良い。
ggplot(cabbage_exp, aes(Date, Weight, fill = Cultivar)) + # x軸にDate、y軸にWeight;fill = Cultivarを追加
geom_bar(stat = "identity", position = "dodge") # 棒グラフ;position = "dodge"が必要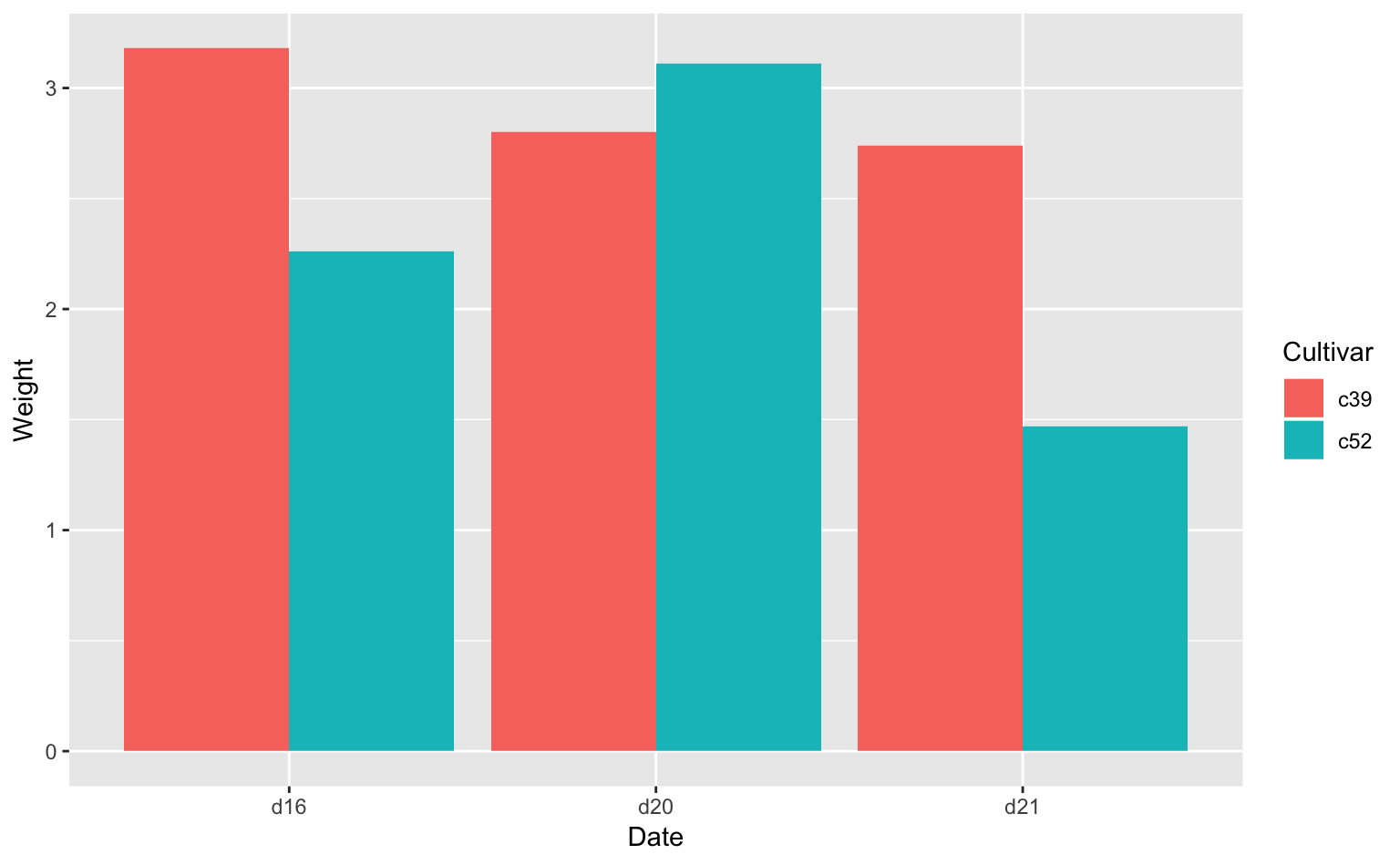
Figure 3.2: グルーピングされた棒グラフ。
このように、2つの変数ごとに棒グラフを描きたい(グルーピングしたい)場合は、fillに変数を追加すれば良い。fillは「塗りつぶし」を意味しており、実際Cultivarの種類に応じて棒が塗りつぶされていることがわかる8。
なお、このようなグラフを描く際は、基本的にposition = "dodge"と指定する必要がある。なぜなら、geom_bar()はデフォルトがposition = "stack"であり、そのままだと積み上げ棒グラフになってしまうからである。ちなみに、position = "fill"と指定すれば、全体を100%にした積み上げ棒グラフを描くことができる。積み上げ棒グラフは割合や比率を表すのによく使われるグラフである。
3.1.3 個数を表す棒グラフ
では、データの数値ではなく、データの個数(カウントデータ)はどのようにプロットすればよいだろうか? 次は、ggplot2のdiamonds(ダイアモンドに関するデータセット)を使ってみよう。
head(diamonds) # 先頭6行## # A tibble: 6 x 10
## carat cut color clarity depth table price x y z
## <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
## 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
## 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
## 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
## 4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
## 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
## 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48ここではcutという変数に着目してみよう。
cut:ダイアモンドのカットの質(Fair, Good, Very Good, Premium, or Ideal)
ダイアモンドの個数をカットに応じてプロットしてみよう。なお、geom_bar()はデータの個数を自動的に数えてくれるので、yに変数を対応づける必要はない。
ggplot(diamonds, aes(cut)) + # x軸にcut;yには何も対応づける必要なし
geom_bar() # 棒グラフ;今回はデータの値ではなく個数を描くので、stat = "identity"は不要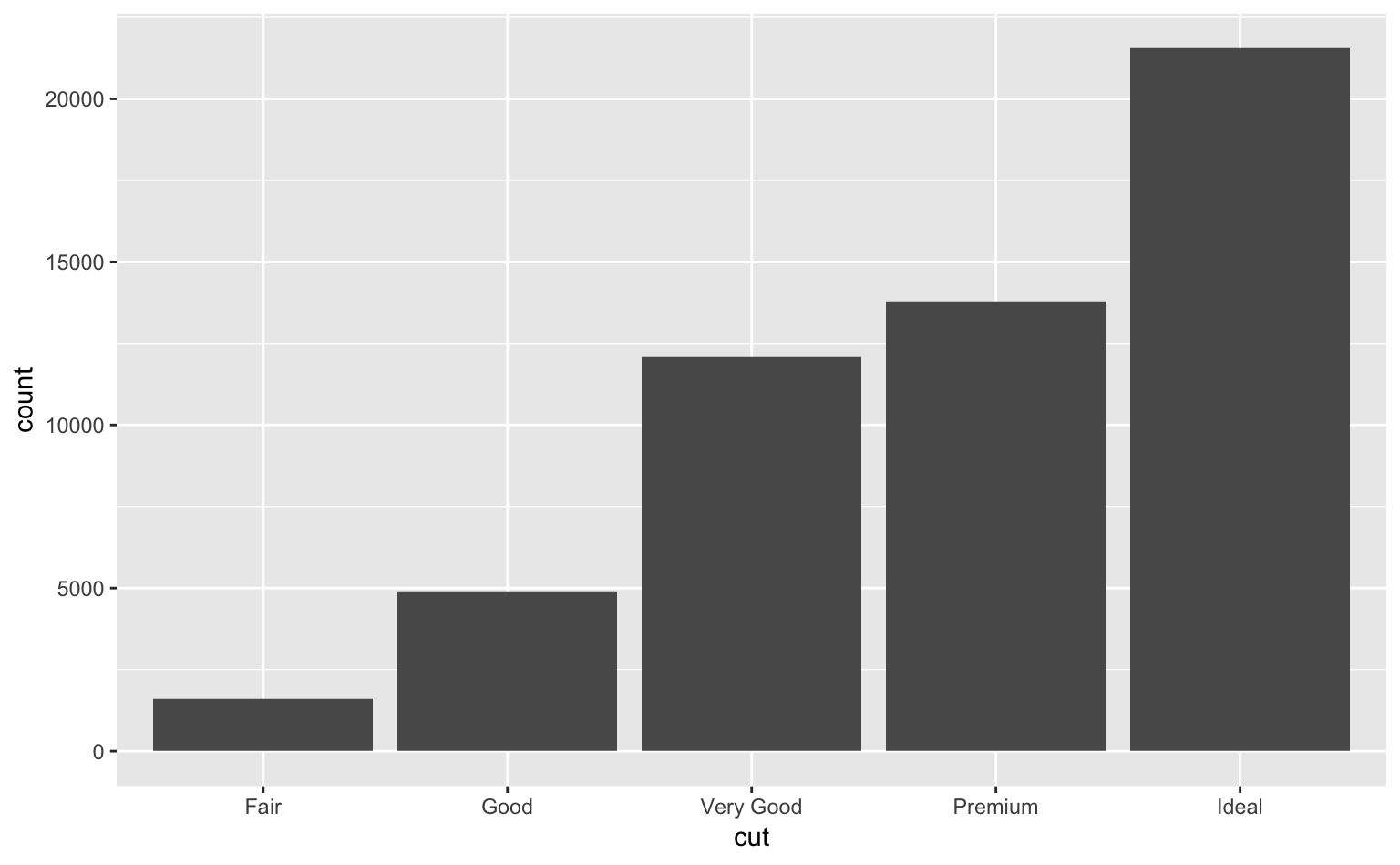
Figure 3.3: カットごとのダイアモンドの個数。
無事に個数をプロットすることができた。
3.2 Clevelandのドットプロット
数量の可視化に向いているのは棒グラフだけではない。というよりもむしろ、棒グラフが可視化に向かない場合もある。たとえば、gcookbookのtophitters2001(2001年MLBの上位144打手のデータセット)を使ってそれを見てみよう。
head(tophitters2001)## id first last name year stint team lg g ab r
## 1 walkela01 Larry Walker Larry Walker 2001 1 COL NL 142 497 107
## 2 suzukic01 Ichiro Suzuki Ichiro Suzuki 2001 1 SEA AL 157 692 127
## 3 giambja01 Jason Giambi Jason Giambi 2001 1 OAK AL 154 520 109
## 4 alomaro01 Roberto Alomar Roberto Alomar 2001 1 CLE AL 157 575 113
## 5 heltoto01 Todd Helton Todd Helton 2001 1 COL NL 159 587 132
## 6 aloumo01 Moises Alou Moises Alou 2001 1 HOU NL 136 513 79
## h 2b 3b hr rbi sb cs bb so ibb hbp sh sf gidp avg
## 1 174 35 3 38 123 14 5 82 103 6 14 0 8 9 0.3501
## 2 242 34 8 8 69 56 14 30 53 10 8 4 4 3 0.3497
## 3 178 47 2 38 120 2 0 129 83 24 13 0 9 17 0.3423
## 4 193 34 12 20 100 30 6 80 71 5 4 9 9 9 0.3357
## 5 197 54 2 49 146 7 5 98 104 15 5 1 5 14 0.3356
## 6 170 31 1 27 108 5 1 57 57 14 3 0 8 18 0.3314変数がたくさんあるが、とりあえず
name:打手の名前avg:打率
に注目してみよう。なお、データが144行と少し多いので、わかりやすさのため先頭の20名のデータだけを使うことにする。20名のデータはtop20hittersに代入する。
top20hitters = tophitters2001[1:20,] # 先頭20行を抽出してtop20hittersに代入それでは、このtop20hittersを使って、まずは打手ごとの打率を素直に棒グラフで描いてみよう。
ggplot(top20hitters, aes(name, avg)) + # x軸にname、y軸にavg
geom_bar(stat = "identity") # 棒グラフ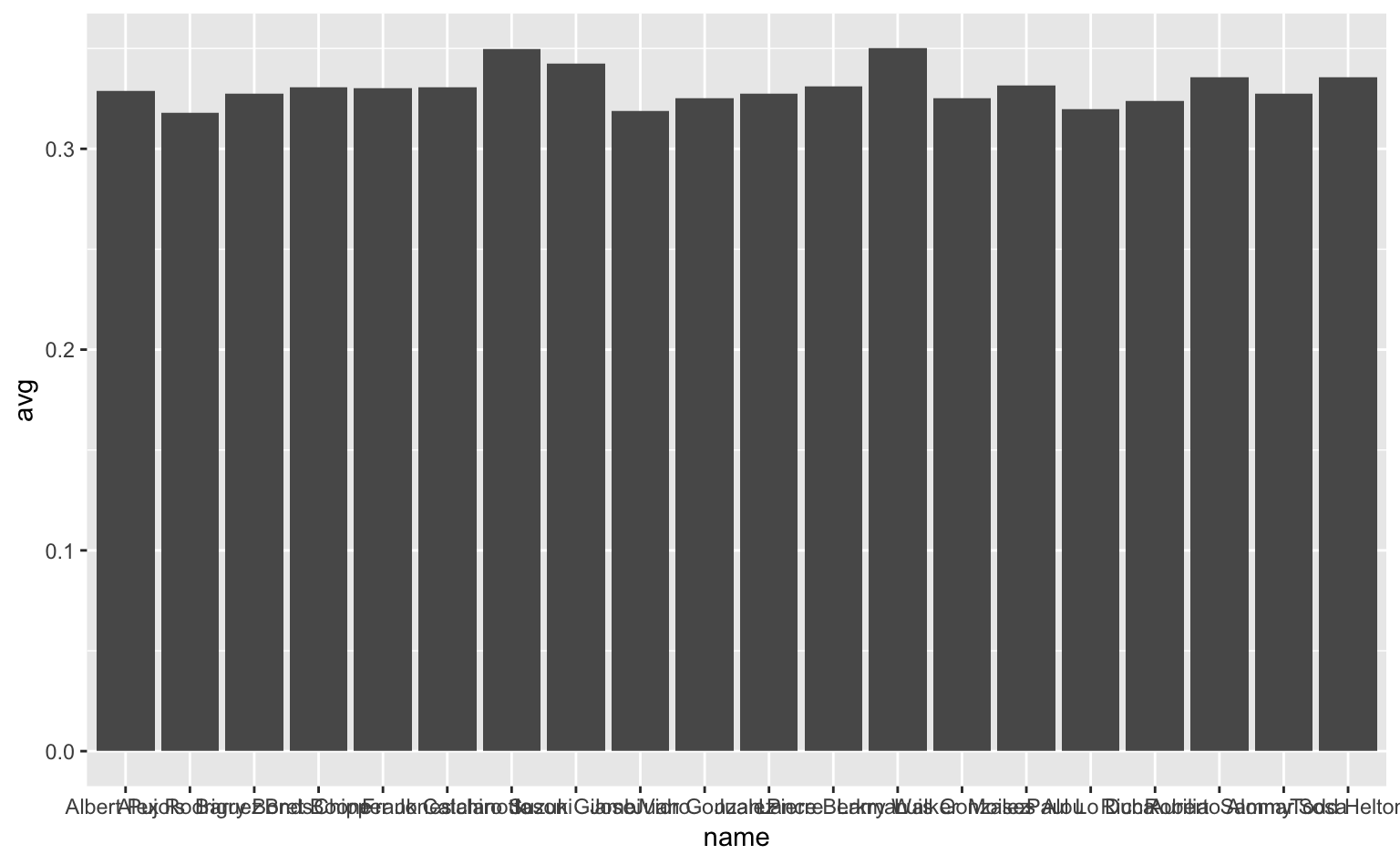
Figure 3.4: 2001年MLBのトップ20の打率。
これを見てどのように思うだろうか? おそらく「あまり美しくない」と感じる人が多いだろう。では、どこが問題なのか。大きく2つの問題点が挙げられるだろう。
問題1. 選手ごとの打率の違いが明確に見えない
- 棒グラフはy = 0から始まるという性質がある9。しかし、今回のデータの値(打率)は基本的に0.3前後なので、y = 0をグラフに含めるとデータの特徴が見えづらくなってしまう。このような場合、棒グラフは可視化に向いていない。
問題2. 打率の高低によって選手が並び替えられていない(ソートされていない)
- これは棒グラフ自体の問題ではないが、可視化において重要なポイントである。これも直す必要があるだろう。
これらの問題に対する解決策の1つとして、Clevelandのドットプロット(Cleveland dot plot)というものがある。ドットプロットというくらいなので、散布図のようにデータをドットで表現する手法である。描き方を順に見ていこう。
ggplot(top20hitters, aes(avg, reorder(name, avg))) + # x軸とy軸を交換、reorder()関数を使う
geom_point() # ドットで描く;stat = "identity"は不要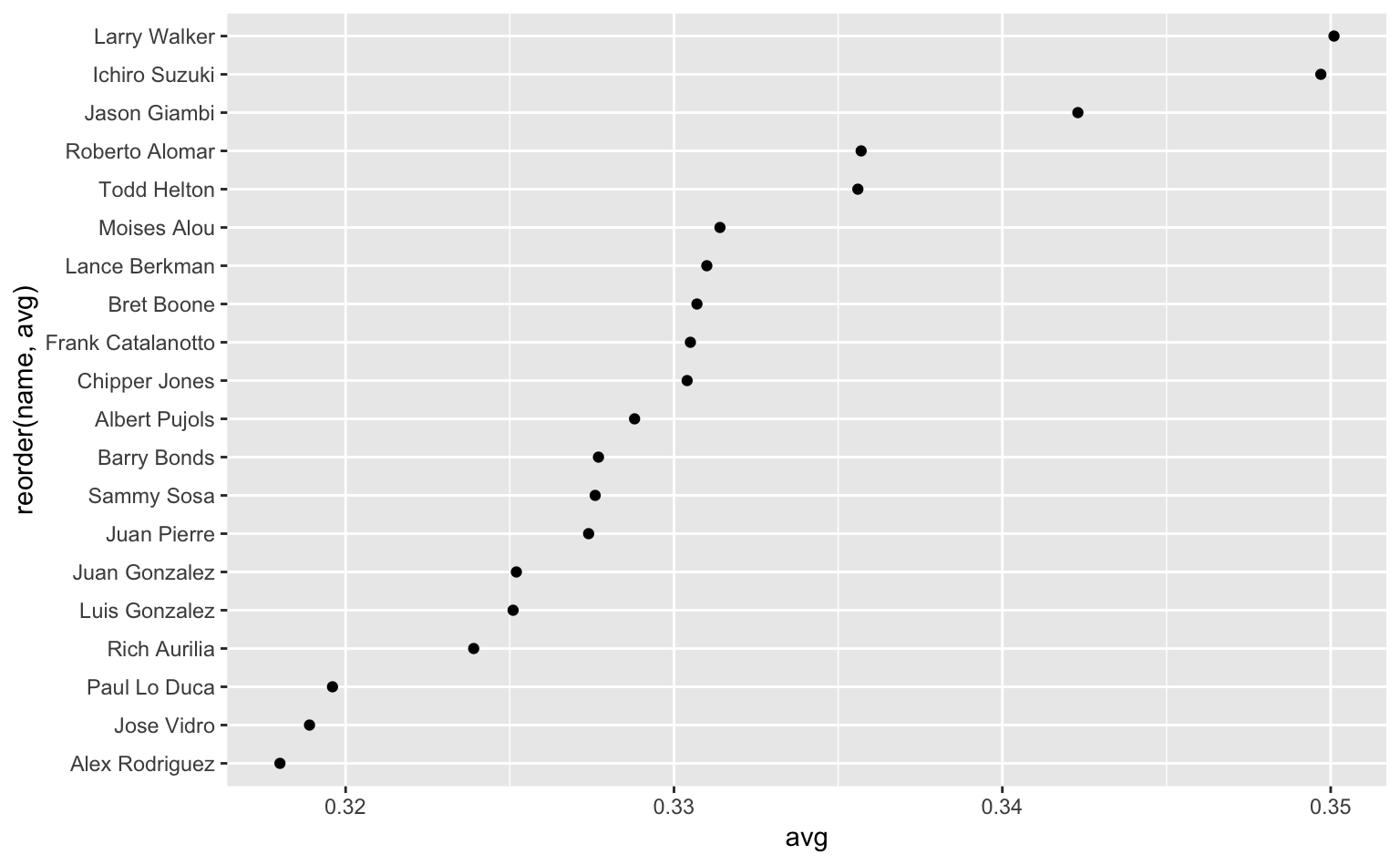
Figure 3.5: Clevelandのドットプロット(2001年MLBトップ20の打率)。
ggplot(top20hitter, aes(avg, reorder(name, avg)))打率をx軸、選手名をy軸にする。こうすることで、選手名が重ならずに済む。
reorder(name, avg)により、選手名を打率でソートしている。reorder(a, b)はaをbの値で(昇順に)ソートする関数である。reorder()は、変数の順序情報を強調する際に使うと効果的である。
geom_point()データをドットで表現するための関数。
ちなみに、
geom_point()ではstat = "identity"がデフォルトである。そのためgeom_bar()とは異なり、statの中身を明示的に指定する必要がない。
これがClevelandのドットプロット10である。改めてFigure 3.4とFigure 3.5を見比べると、明らかにグラフの見栄えが改善していることがわかる。
3.3 練習問題
cabbage_expのデータを使い、x軸にCultivar、y軸にWeight、Dateで色分けした棒グラフを描いてみよう。diamondsのデータを使い、clarity(輝きの等級)ごとにダイアモンドの個数をプロットしてみよう。gcookbookの
uspopchangeのデータ構造を確認しよう(?uspopchangeとhead(uspopchange))。その上で、この章で学んだテクニックを使い、州ごとに人口がどれくらい増減したかをプロットしてみよう。また、どのようなデザインでプロットするのが最も妥当かつ見栄えが良いかを考えてみよう。
ここら辺のことはいずれわかるようになるので、今はそういうものだと飲み込んでほしい。いずれ勝手に理解できているはず(たぶん)。↩
本資料のコードを修正した上で実行してもPCが壊れたりすることはないので、「ここをこうしたらどうなるだろうか?」と積極的にいじってみることを推奨する。↩
異論は認めない。↩
「色なのだから、
colorに変数を指定するのでは?」と思った人がいるかもしれない。実際、geom_bar()でcolorに変数を指定すると、棒の枠線の色が変わる。しかし、棒グラフの枠に色をつけてもごちゃごちゃするだけなので、基本的には変数を指定する必要はない。↩逆に、y = 0から始まっていない棒グラフを見た場合、少し疑ってかかったほうが良い。このような棒グラフは結構巷にあふれている。↩
類似のグラフとしてロリポッププロット(lollipop plot; lollipop chart)というものもある。https://python-graph-gallery.com/lollipop-plot/↩